Hadoop Architecture
1. Hadoop의 시작
더그 커팅(Doug Cutting)
루씬 제작자
- 검색엔진용 오픈소스
- 텍스트 인덱스 엔진
2. Hadoop의 역사
- 구글 검색엔진과 같은 대형 검색엔진 제작에 관심
- 데이터를 대량으로 저장할 수 있는 빅파일시스템과 분산처리구조에 관심을 가지고 있었음
- 구글의 두 가지 논문에 영감을 얻어 Hadoop을 제작
- The Google File System(2003)
- MapReduce : Simplified Data Processing on Large Cluster(2004)
- 2006년부터 제작(Apache Top Level Project)
- 야후에 취직 → 클라우데라로 이직
- GFS → HDFS, MapReduce → MapReduce
Hadoop의 기본사항과 특징
1. Hadoop의 기초
- JAVA기반
- Unix기반에서 주로 사용
- MS가 윈도우 기반으로 포팅하고 있으나 파일시스템 요구사항을 맞추기 쉽지 않음
- Linux Ubuntu 사용 예정
- 배포판
- Apache Hadoop, CDH(클라우데라판), HDP(호튼웍스판)...
- Hadoop의 빅3 회사
- Apache 재단
- Claudera
- HortonWorks
- MapR(구글/아마존과 협업)
2. Hadoop의 특징
- Open Source cf.github
- 데이터가 있는 곳으로 코드를 이동
- Scale Out(서버 수천대 연결 가능) vs Scale Up
- 병렬처리를 가능하게 하도록 단순화 시킨 데이터 모델
- 오프라인 배치 프로세싱에 최적화
- 실시간 처리가 안됨 - 데이터가 저장되면 처리해서 결과를 반영하는 방식
- Hadoop 이후로 real-time processing of streaming big data 처리가 나오고 있다.
3. Hadoop Architecture
💡 Hadoop = HDFS(Hadoop File System) + MapReduce
- Big File System : HDFS
- NameNode(Master)/DataNode(slave)
- secondary NameNode(보조 네임노드 - 하둡의 약점)
- SPOF(Single Point Of Failure)문제
- Distributed Processing(분산처리) Framework : MapReduce
- JobTracker(Master)/TaskTracker(slave)
- TaskTracker가 Map Task, Reduce Task 관리
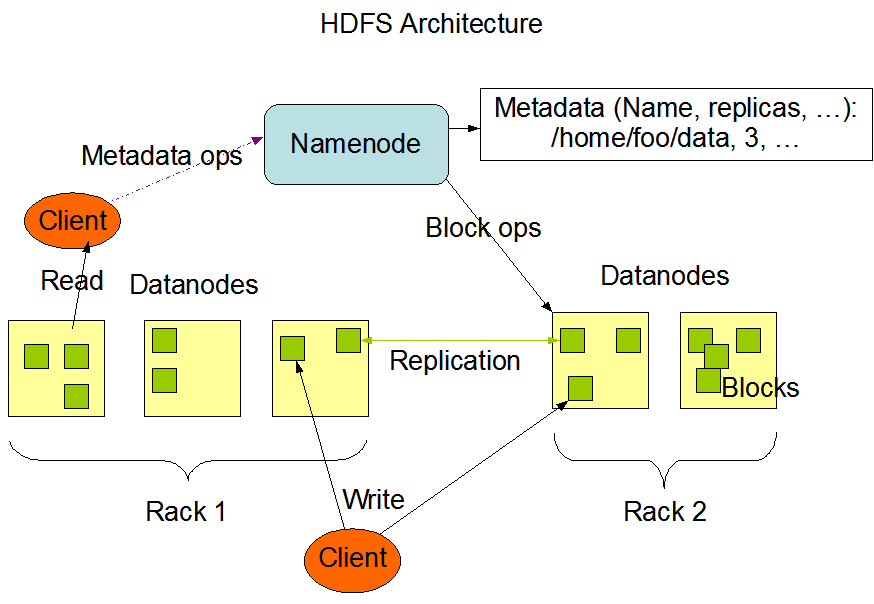
4. HDFS
- 전체가 하나의 HDFS에 하나의 Name space 제공
- 윈도우는 드라이브 별로 루트가 있다.
- Unix는 시스템 전체에 루트가 하나뿐이어서 /dev/data ← 이런식으로 여러 개의 폴더가 생성되면서 mount 되는 방식이다
- HDFS는 시스템이 Unix 같은 시스템이 여러 개가 되기 때문에 여러 대의 시스템을 다 묶어서 하나의 루트가 있다.(논리적 루트)
- 하나의 파일을 여러 개의 블럭으로 나누어 저장
- 기존의 하드디스크와 SSD는 cluster(4KB), secter(512Byte) 단위로 데이터를 나눈다
- Block Size : 64MB(실제로 128MB 많이 사용)
- 큰 파일을 다루는데 적합
- 포맷이 다르지만 운영체제의 파일시스템을 오버레이 해서 그대로 사용한다
- 복제수(Replication Factor)
- 서버가 장애를 일으켜서 접근이 안되거나 네트워크 장애로 접근이 안될 때도 액세스에 문제 되지 않도록 동일한 블럭을 여러 개의 데이터 모드에 나눠서 저장한다.
- HA : High Availability
- Write Once Read Many
- File Overwrite not Append- 주로 큰 파일을 다루기 때문에 append가 아닌 덮어쓰기 형식으로 동작한다

5. JobTracker
- Job : 하나의 MapReduce 프로그램
- 하나의 Job은 여러 개의 Map Task와 Reduce Task로 이루어짐
- TaskTracker : 2개의 Map Task와 2개의 Reduce Task(기본)
- 역할
- User Hadoop Job Execution Request(jar file, Input data place, Output data place) 받아서
- Job Task들을 TaskTracker로 나눠서 실행하고 종료할 때까지 관리
- Input data / Output data 위치는 반드시 HDFS상에 존재해야 함
- Task Tracker는 DataNode와 같은 Physical Server에 존재
6. MapReduce Framework

💡 현재 Mapper가 3개, Reduce가 4개 있는 상태 물리적인 데이터가 저장되면 Splitting되어 각 데이터를 물리적으로 1/3으로 나눠서 각 Mapper로 보내준다. word count 각 단어가 몇 번씩 나왔는지 카운팅함 Key/Value 방식으로 각 맵퍼들이 자기의 작업으로 처리하면 Shuffling과 Sorting작업을 거쳐 원하는 작업만 모듈로 분리해서 처리할 수 있게 된다. 처리할 대상을 지정해서 원하는 Reducer로 보내 작업한다.
전반적인 작업을 Hadoop Frameword가 대신 해준다.
작업자의 역할은
- Input
- 데이터 수입
- Mapper
- 어떤 형태의 Mapping을 처리할 것인지 결정
- Reducer
- 어떤 형태의 Reduce를 처리할 것인지 결정
반응형
'Data Science > Hadoop' 카테고리의 다른 글
| [Hadoop] hadoop 성공사례 및 기초 개념 (0) | 2022.03.09 |
|---|---|
| 빅데이터 정리 (0) | 2022.03.08 |
| 빅데이터 마케팅 (0) | 2021.09.14 |
| 1. 빅데이터 개요 (0) | 2021.02.01 |

댓글